Gemma 4 de Google...
Posté : sam. 4 avr. 2026 06:25
Gemma 4 de Google : l'IA locale open source qui veut s'infiltrer partout
Google change de stratégie et abat une carte maîtresse sur la table de l'IA locale. Avec Gemma 4, le géant de la tech ne propose plus seulement un modèle puissant, mais un véritable écosystème ouvert, conçu pour tourner sur nos appareils du quotidien, du smartphone à la station de travail.
 Google lance Gemma 4, une nouvelle famille de modèles d'IA open source basés sur l'architecture de Gemini 3. Proposée en quatre tailles (2B, 4B, 26B MoE, 31B Dense), elle vise à offrir des capacités de raisonnement complexe et de gestion d'agents IA en local, sur des appareils à faible consommation. La grande nouveauté est sa licence Apache 2.0, qui offre une liberté totale aux développeurs.
Google lance Gemma 4, une nouvelle famille de modèles d'IA open source basés sur l'architecture de Gemini 3. Proposée en quatre tailles (2B, 4B, 26B MoE, 31B Dense), elle vise à offrir des capacités de raisonnement complexe et de gestion d'agents IA en local, sur des appareils à faible consommation. La grande nouveauté est sa licence Apache 2.0, qui offre une liberté totale aux développeurs.
Google ne se contente plus de dominer la recherche et le cloud. L'entreprise met le paquet sur l'intelligence artificielle locale, celle qui s'exécute directement sur nos machines, sans dépendre d'une connexion internet permanente.
Avec le lancement de sa nouvelle famille de modèles, Gemma 4, la firme de Mountain View envoie un signal fort au marché. Développés à partir des mêmes technologies que le très propriétaire Gemini 3, ces modèles sont conçus pour une chose : démocratiser l'accès à une IA de pointe.
Disponibles sur les grandes plateformes IA, ils ciblent aussi bien les smartphones Android que les puissantes stations de travail équipées de GPU dédiés, avec l'ambition de créer un standard de fait pour l'IA embarquée.
Qu'est-ce que Gemma 4 et en quoi est-il différent de Gemini ?
Gemma 4 est une famille de modèles d'IA dits « ouverts » (open-weight), dont Google fournit les poids pré-entraînés, permettant aux développeurs de les utiliser et de les adapter.
Contrairement à Gemini, qui est un produit final propriétaire et un service cloud, Gemma 4 est une boîte à outils. La gamme se décline en quatre variantes pour couvrir tous les besoins.
Les modèles Effective 2B et 4B (pour 2 et 4 milliards de paramètres) sont taillés pour les appareils à faible puissance comme les smartphones ou les Raspberry Pi.
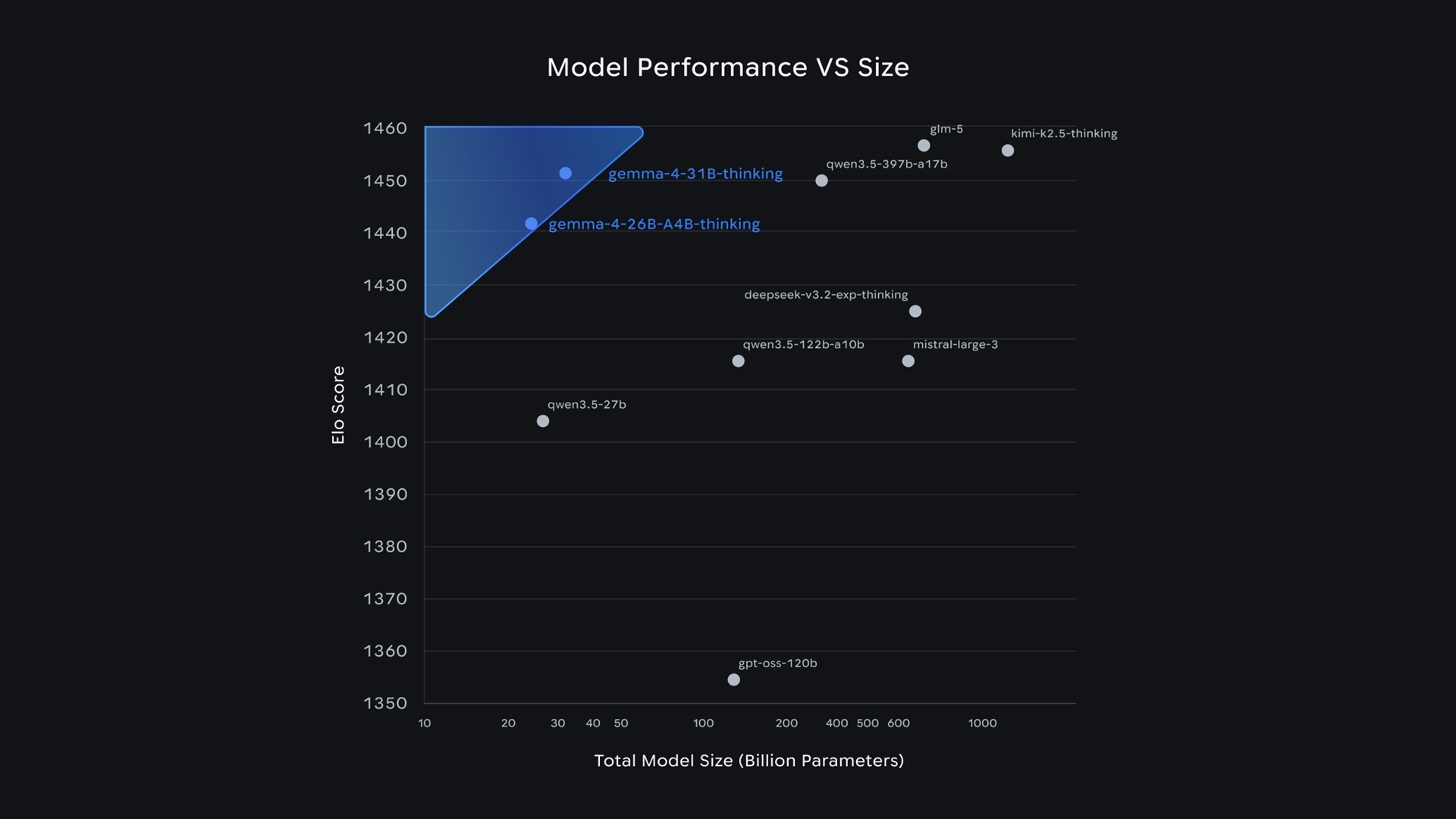 Les versions plus musclées, un 26B Mixture of Experts (MoE) et un 31B Dense, visent les stations de travail et les serveurs locaux. Cette approche modulaire permet d'obtenir un niveau d'« intelligence-par-paramètre » inédit, où même les petits modèles surclassent des concurrents bien plus volumineux.
Les versions plus musclées, un 26B Mixture of Experts (MoE) et un 31B Dense, visent les stations de travail et les serveurs locaux. Cette approche modulaire permet d'obtenir un niveau d'« intelligence-par-paramètre » inédit, où même les petits modèles surclassent des concurrents bien plus volumineux.
Quelles sont les capacités concrètes de la famille Gemma 4 ?
La gamme ne se contente pas de bavarder. Elle agit. Grâce à la prise en charge native de l'appel de fonctions (function calling) et des sorties en format JSON structuré, les modèles Gemma 4 sont conçus pour piloter des charges de travail agentiques.
En clair, ils peuvent interagir avec d'autres logiciels, lancer des commandes et exécuter des plans en plusieurs étapes de manière autonome. C'est la porte ouverte à des assistants locaux capables de gérer votre agenda, de trier vos fichiers ou d'automatiser des tâches complexes.
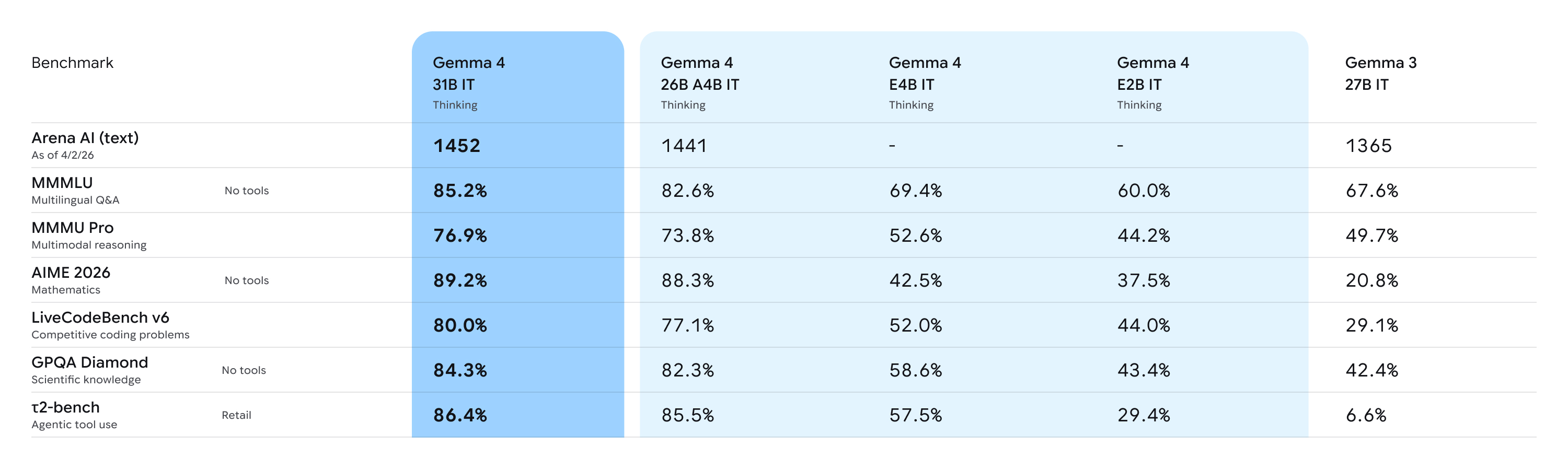 Toutes les versions sont multimodales, capables de traiter des images et des vidéos, ce qui est idéal pour des tâches de reconnaissance de caractères (OCR) ou d'analyse de graphiques.
Toutes les versions sont multimodales, capables de traiter des images et des vidéos, ce qui est idéal pour des tâches de reconnaissance de caractères (OCR) ou d'analyse de graphiques.
Les petites versions E2B et E4B vont plus loin en intégrant une compréhension audio native pour la reconnaissance vocale en temps réel. Avec des fenêtres de contexte allant jusqu'à 256 000 tokens, ils peuvent analyser d'énormes documents ou des bases de code entières en une seule fois.
Pourquoi le passage à la licence Apache 2.0 est-il si important ?
C'est peut-être le point le plus stratégique de cette annonce. Les précédentes versions de Gemma étaient distribuées sous une licence personnalisée qui imposait des restrictions commerciales.
Avec Gemma 4, Google bascule sur la licence Apache 2.0, une référence dans le monde des logiciels open source. Ce changement offre une liberté quasi totale aux développeurs et aux entreprises pour modifier, utiliser et redistribuer les modèles, y compris à des fins commerciales, sans avoir à verser de royalties.
Cette décision lève les barrières et encourage une adoption massive. Pour les entreprises, c'est une garantie de souveraineté numérique qui leur permet de garder un contrôle total sur leurs données et leur infrastructure, que ce soit en local (on-premises) ou sur un cloud privé.
Comment les développeurs peuvent-ils utiliser et accéder à Gemma 4 ?
Google a simplifié au maximum l'accès à ses nouveaux modèles. Les poids sont téléchargeables directement depuis des plateformes communautaires de premier plan comme Hugging Face, Kaggle et Ollama.
Les versions les plus avancées (26B et 31B) sont optimisées pour tourner sur un unique GPU NVIDIA H100 mais des versions quantifiées (c'est à dire compressées pour exiger moins de ressources) peuvent fonctionner sur des cartes graphiques grand public.
Les plus petits modèles, eux, ont été co-optimisés avec Qualcomm et MediaTek pour une efficacité maximale sur les puces mobiles.
L'écosystème d'outils compatibles est déjà impressionnant, incluant des frameworks populaires comme Keras, vLLM ou llama.cpp. Cette offensive sur le front de l'IA locale, menée par les chercheurs de Google DeepMind, est une stratégie redoutable.
En offrant des outils puissants et ouverts, Google s'assure que des millions de développeurs apprendront à construire avec ses technologies. C'est, à long terme, un coup de maître pour bâtir un écosystème captif autour de son savoir-faire, même en dehors de son propre cloud.
merci à GNT
Google change de stratégie et abat une carte maîtresse sur la table de l'IA locale. Avec Gemma 4, le géant de la tech ne propose plus seulement un modèle puissant, mais un véritable écosystème ouvert, conçu pour tourner sur nos appareils du quotidien, du smartphone à la station de travail.
Google lance Gemma 4, une nouvelle famille de modèles d'IA open source basés sur l'architecture de Gemini 3. Proposée en quatre tailles (2B, 4B, 26B MoE, 31B Dense), elle vise à offrir des capacités de raisonnement complexe et de gestion d'agents IA en local, sur des appareils à faible consommation. La grande nouveauté est sa licence Apache 2.0, qui offre une liberté totale aux développeurs.Google ne se contente plus de dominer la recherche et le cloud. L'entreprise met le paquet sur l'intelligence artificielle locale, celle qui s'exécute directement sur nos machines, sans dépendre d'une connexion internet permanente.
Avec le lancement de sa nouvelle famille de modèles, Gemma 4, la firme de Mountain View envoie un signal fort au marché. Développés à partir des mêmes technologies que le très propriétaire Gemini 3, ces modèles sont conçus pour une chose : démocratiser l'accès à une IA de pointe.
Disponibles sur les grandes plateformes IA, ils ciblent aussi bien les smartphones Android que les puissantes stations de travail équipées de GPU dédiés, avec l'ambition de créer un standard de fait pour l'IA embarquée.
Qu'est-ce que Gemma 4 et en quoi est-il différent de Gemini ?
Gemma 4 est une famille de modèles d'IA dits « ouverts » (open-weight), dont Google fournit les poids pré-entraînés, permettant aux développeurs de les utiliser et de les adapter.
Contrairement à Gemini, qui est un produit final propriétaire et un service cloud, Gemma 4 est une boîte à outils. La gamme se décline en quatre variantes pour couvrir tous les besoins.
Les modèles Effective 2B et 4B (pour 2 et 4 milliards de paramètres) sont taillés pour les appareils à faible puissance comme les smartphones ou les Raspberry Pi.
Les versions plus musclées, un 26B Mixture of Experts (MoE) et un 31B Dense, visent les stations de travail et les serveurs locaux. Cette approche modulaire permet d'obtenir un niveau d'« intelligence-par-paramètre » inédit, où même les petits modèles surclassent des concurrents bien plus volumineux.Quelles sont les capacités concrètes de la famille Gemma 4 ?
La gamme ne se contente pas de bavarder. Elle agit. Grâce à la prise en charge native de l'appel de fonctions (function calling) et des sorties en format JSON structuré, les modèles Gemma 4 sont conçus pour piloter des charges de travail agentiques.
En clair, ils peuvent interagir avec d'autres logiciels, lancer des commandes et exécuter des plans en plusieurs étapes de manière autonome. C'est la porte ouverte à des assistants locaux capables de gérer votre agenda, de trier vos fichiers ou d'automatiser des tâches complexes.
Toutes les versions sont multimodales, capables de traiter des images et des vidéos, ce qui est idéal pour des tâches de reconnaissance de caractères (OCR) ou d'analyse de graphiques.Les petites versions E2B et E4B vont plus loin en intégrant une compréhension audio native pour la reconnaissance vocale en temps réel. Avec des fenêtres de contexte allant jusqu'à 256 000 tokens, ils peuvent analyser d'énormes documents ou des bases de code entières en une seule fois.
Pourquoi le passage à la licence Apache 2.0 est-il si important ?
C'est peut-être le point le plus stratégique de cette annonce. Les précédentes versions de Gemma étaient distribuées sous une licence personnalisée qui imposait des restrictions commerciales.
Avec Gemma 4, Google bascule sur la licence Apache 2.0, une référence dans le monde des logiciels open source. Ce changement offre une liberté quasi totale aux développeurs et aux entreprises pour modifier, utiliser et redistribuer les modèles, y compris à des fins commerciales, sans avoir à verser de royalties.
Cette décision lève les barrières et encourage une adoption massive. Pour les entreprises, c'est une garantie de souveraineté numérique qui leur permet de garder un contrôle total sur leurs données et leur infrastructure, que ce soit en local (on-premises) ou sur un cloud privé.
Comment les développeurs peuvent-ils utiliser et accéder à Gemma 4 ?
Google a simplifié au maximum l'accès à ses nouveaux modèles. Les poids sont téléchargeables directement depuis des plateformes communautaires de premier plan comme Hugging Face, Kaggle et Ollama.
Les versions les plus avancées (26B et 31B) sont optimisées pour tourner sur un unique GPU NVIDIA H100 mais des versions quantifiées (c'est à dire compressées pour exiger moins de ressources) peuvent fonctionner sur des cartes graphiques grand public.
Les plus petits modèles, eux, ont été co-optimisés avec Qualcomm et MediaTek pour une efficacité maximale sur les puces mobiles.
L'écosystème d'outils compatibles est déjà impressionnant, incluant des frameworks populaires comme Keras, vLLM ou llama.cpp. Cette offensive sur le front de l'IA locale, menée par les chercheurs de Google DeepMind, est une stratégie redoutable.
En offrant des outils puissants et ouverts, Google s'assure que des millions de développeurs apprendront à construire avec ses technologies. C'est, à long terme, un coup de maître pour bâtir un écosystème captif autour de son savoir-faire, même en dehors de son propre cloud.
merci à GNT